tl;dr: We gave Claude Code a custom /review-agent-trace skill with examples of common failure modes and instructions for forming, testing, and iterating on hypotheses. It now catches scaffolding issues, tool failures, prompt-induced issues, and reasoning failures in our agent traces that we'd overlook when skimming manually. Earlier attempts with Sonnet 3.7 required splitting analysis across dozens of narrow prompts applied to every individual ReAct step, which was expensive, brittle, and still missed a lot. Opus 4.6-powered Claude Code handles the full trace in a single session without human intervention with a general prompt, and it actually works.
At FutureSearch I spend a lot of time reading agent traces. Partly to know how to improve our agents, and partly to verify that evals we run can be trusted. The things I'm looking for range from scaffolding bugs (misconfigured system prompts, agents accidentally stopping under certain conditions) to tool failures like searches returning gibberish, to prompt-induced problems like overly narrow framing or conflicting instructions. And then, that leaves the hardest category: reasoning failures where the agent gets confused about dates, makes erratic tool calls, or ignores parts of the task description.
Once I find an issue, I often have to try several changes to our agent architecture/system prompts/infrastructure to iron things out again.
Now Claude Code isn't great at automating this right out of the box*, but we can have it write its own /review-agent-trace skill† by prompting it with a bunch of examples of the kind of things to look out for, as well as some instructions how to form hypotheses and run quick experiments to check and iterate on them.
And this works really well, often spotting issues that I would have overlooked when only quickly skimming a trace. Here are two example outputs for a simple review this trace: <link to Langfuse trace> command:
1)
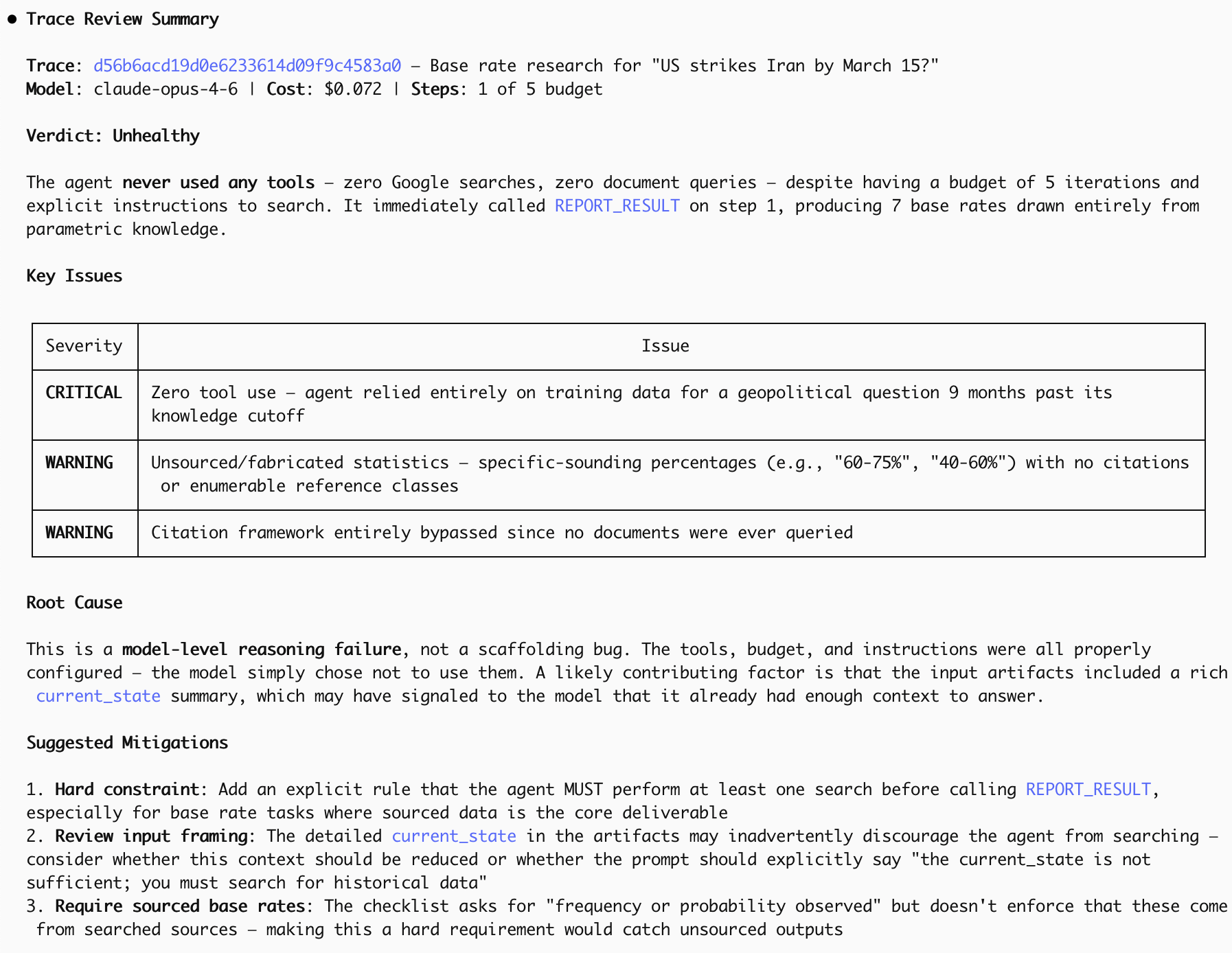
The issue at hand is that the agent should have issued some Google calls. Had it done so, it would have been aware of rising US-Iranian tensions. (It turns out this is a general problem of Opus 4.6 with effort = low; using effort = medium appears to be enough to fix this, at least in this case.)
2)

The issue it found was that, when tasked with finding the highest closing price between mid April and November, the first dataset our agent found only covered October, but this was enough to make said agent stop and report the (incorrect) result. If asked why this happened and to suggest a fix, it then simulated some more ReAct agent steps with modified prompts and found this:
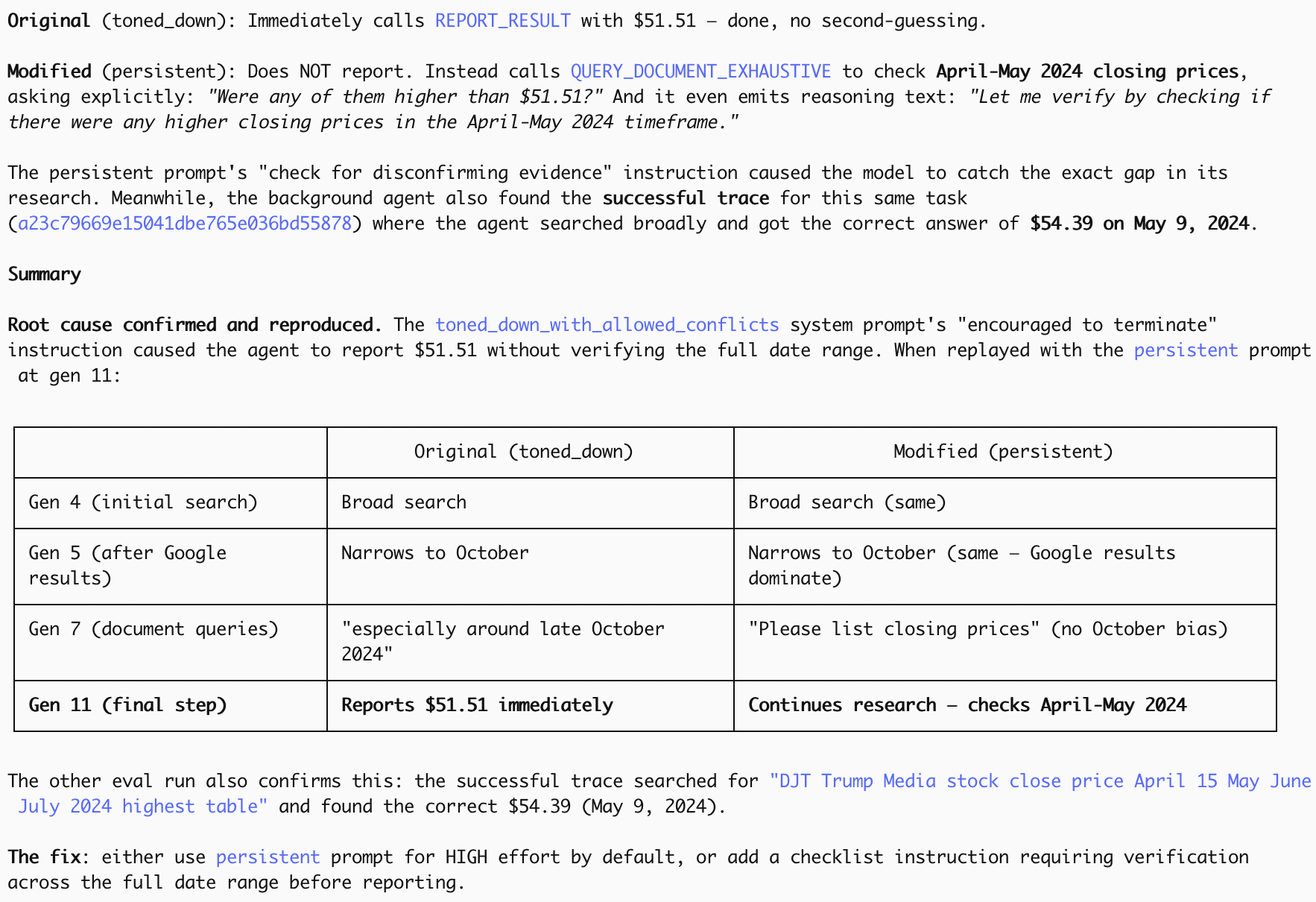
I'm pretty excited about this because we've been trying to use LLMs to analyse our agents' traces for a while. The first time this kind of worked was with Sonnet 3.7 (see our DRB paper), but there were some pretty serious limitations:
A general prompt like "find issues with this trace" (and more cleverly augmented variations of this) wouldn't work as Sonnet was just too trusting: When agents said "ok, now I found the right answer …", it would often just take this at face value, no matter how sceptical you tried to make it via prompt engineering. Instead we went with multiple narrow, more specialised prompts, e.g. one checking for hallucinations, one for incorrect tool usage, one for reasoning errors, and many more. But even this failed to pick up many instances of these issues. So ultimately we went with applying these checks to every ReAct agent step individually. This significantly improved accuracy, but it ended up being prohibitively expensive to run at scale.
It also ended up being brittle and quite a pain to maintain: Changes to our ReAct agents would require us to update certain prompts and even the code to run this.
TLDR: It was too expensive, didn't work well enough (as it only caught failure modes humans previously thought of and implemented), and slowed down development/introduced a considerable amount of tech debt.
Footnotes
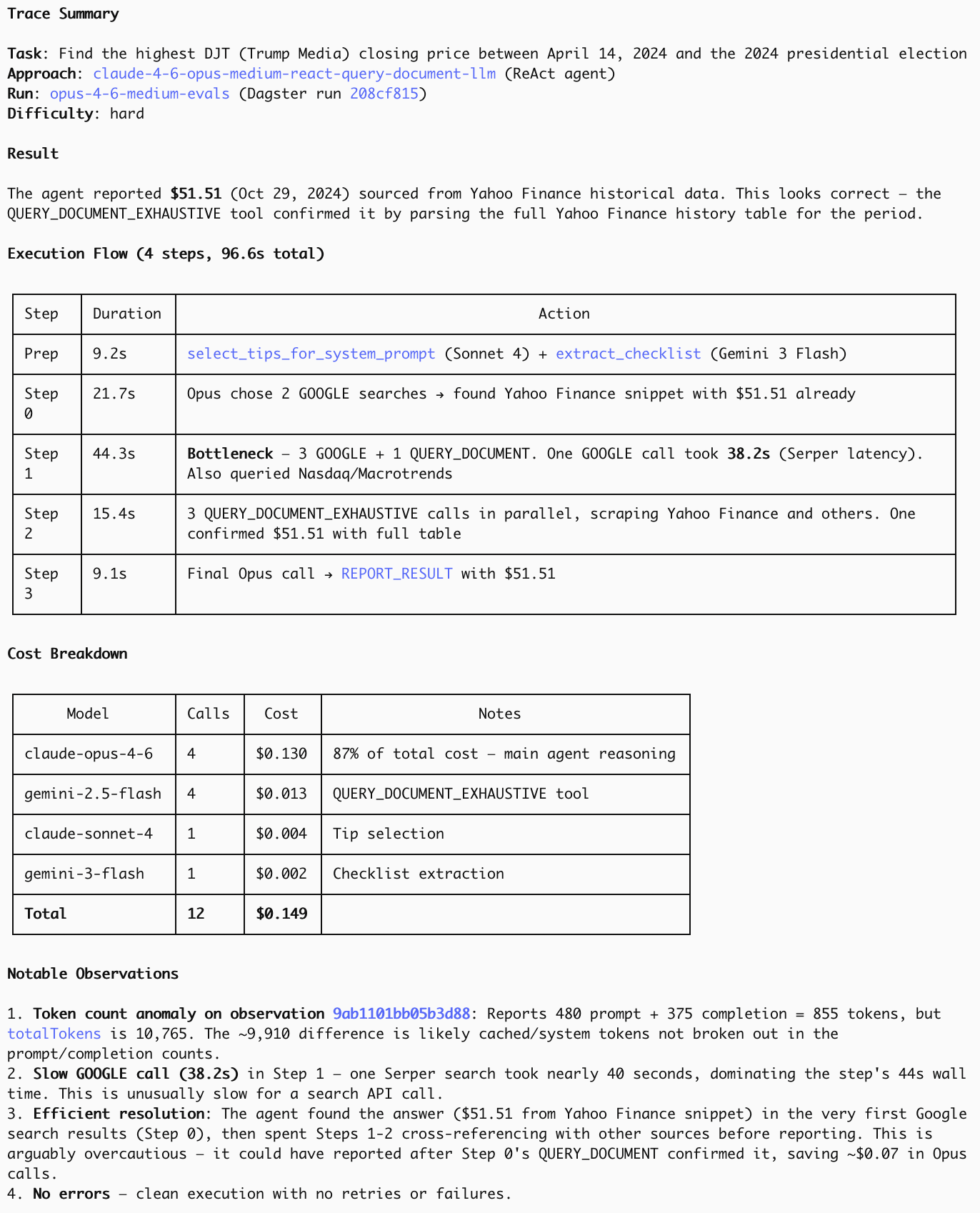
(*): See e.g. this response to review this trace: <link to Langfuse trace>; note how it fails to check what the right answer is and completely misses the issue of our agent only having checked numbers for October, rather than the required period of April–November.
(†): It really pays off to also include some instructions on how to get traces, which Python files to check for our agent implementation, which Python files to check to get the solutions to our evaluation tasks to save it having to figure it all out from scratch every time it's called. This works really well in conjunction with a CLAUDE.md file that encourages Claude Code to update its own skills whenever it finds that some instruction doesn't work anymore, hence keeping the required maintenance for this more or less non-existent!
Related
- Caution: Read the Docs for Claude 4.6's Effort Parameter
- Anthropic Is the Only Frontier Lab Where Reasoning Effort Scales on Deep Research Bench
- Higher effort settings in LLMs can reduce accuracy
- Deep Research Benchmark: Evaluating LLM Web Research Agents
FutureSearch lets you run your own team of AI researchers and forecasters on any dataset. Try it for yourself.