How to Replace Human Data Annotators with LLMs in Active Learning
Human data labeling is slow and expensive. We replaced the human annotator with an LLM oracle in an active learning loop and achieved identical classifier performance — 200 labels in under 5 minutes for $0.26.
Install
pip install everyrow
export EVERYROW_API_KEY=your_key_here # Get one at everyrow.io/api-key
Experiment design
Active learning reduces labeling costs by letting the model choose which examples to label next, focusing on the ones it is most uncertain about. But you still need an oracle to provide those labels, traditionally a human annotator.
We used a TF-IDF + LightGBM classifier with entropy based uncertainty sampling. Each iteration selects the 20 most uncertain examples, sends them to the LLM for annotation, and retrains. 10 iterations, 200 labels total.
We ran 10 independent repeats with different seeds, each time running both a ground truth oracle (human labels) and the LLM oracle with the same seed, a direct, controlled comparison.
from typing import Literal
import pandas as pd
from pydantic import BaseModel, Field
from everyrow import create_session
from everyrow.ops import agent_map
from everyrow.task import EffortLevel
LABEL_NAMES = {
0: "Company", 1: "Educational Institution", 2: "Artist",
3: "Athlete", 4: "Office Holder", 5: "Mean Of Transportation",
6: "Building", 7: "Natural Place", 8: "Village",
9: "Animal", 10: "Plant", 11: "Album", 12: "Film", 13: "Written Work",
}
CATEGORY_TO_ID = {v: k for k, v in LABEL_NAMES.items()}
class DBpediaClassification(BaseModel):
category: Literal[
"Company", "Educational Institution", "Artist",
"Athlete", "Office Holder", "Mean Of Transportation",
"Building", "Natural Place", "Village",
"Animal", "Plant", "Album", "Film", "Written Work",
] = Field(description="The DBpedia ontology category")
async def query_llm_oracle(texts_df: pd.DataFrame) -> list[int]:
async with create_session(name="Active Learning Oracle") as session:
result = await agent_map(
session=session,
task="Classify this text into exactly one DBpedia ontology category.",
input=texts_df[["text"]],
response_model=DBpediaClassification,
effort_level=EffortLevel.LOW,
)
return [CATEGORY_TO_ID.get(result.data["category"].iloc[i], -1)
for i in range(len(texts_df))]
Results
| Metric | Value |
|---|---|
| Labels per run | 200 |
| Cost per run | $0.26 |
| Cost per labeled item | $0.0013 |
| Final accuracy (LLM) | 80.7% ± 0.8% |
| Final accuracy (human) | 80.6% ± 1.0% |
| LLM–human label agreement | 96.1% ± 1.6% |
| Repeats | 10 |
| Dataset | DBpedia-14 (14-class text classification) |
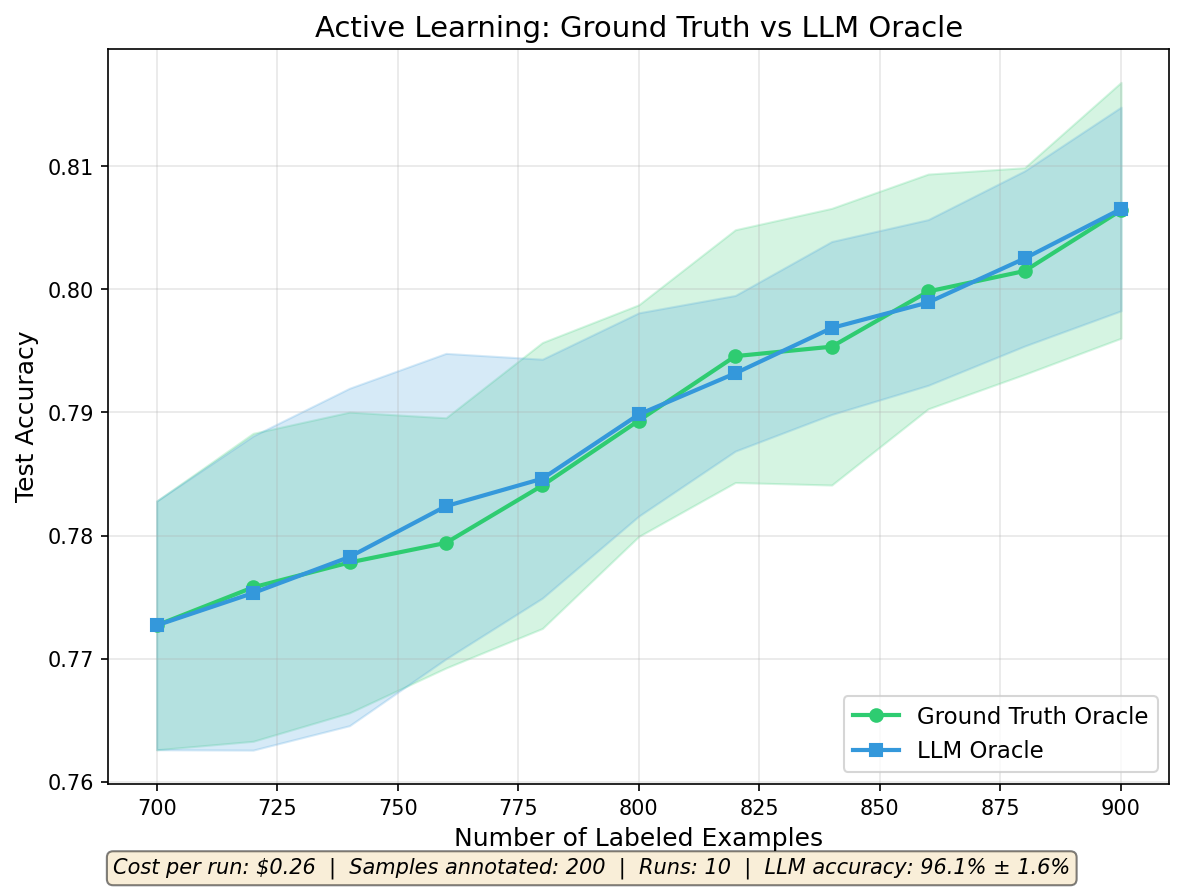
The learning curves overlap almost perfectly. The shaded bands show ±1 standard deviation across 10 repeats — the LLM oracle tracks the ground truth oracle at every iteration.
Final test accuracies averaged over 10 repeats:
| Data Labeling Method | Final Accuracy (mean ± std) |
|---|---|
| Human annotation (ground truth) | 80.6% ± 1.0% |
| LLM annotation (everyrow) | 80.7% ± 0.8% |
The LLM oracle is within noise of the ground truth baseline. Automated data labeling produces classifiers just as good as human labeled data.
The LLM agreed with ground truth labels 96.1% ± 1.6% of the time. Roughly 1 in 25 labels disagrees with the human annotation, but that does not hurt the downstream classifier.
| Metric | Value |
|---|---|
| Cost per run (200 labels) | $0.26 |
| Cost per labeled item | $0.0013 |
| Total (10 repeats) | $2.58 |
200 labels in under 5 minutes for $0.26, fully automated.
Limitations
We tested on one dataset with well separated categories. More ambiguous labeling tasks may see a gap between human and LLM annotation quality. We used a simple classifier (TF-IDF + LightGBM); neural models that overfit individual examples may be less noise tolerant.
The low cost in this experiment comes from using EffortLevel.LOW, which selects a small, fast model and doesn't use web research to improve the label quality. For simple classification tasks with well separated categories, this is sufficient.
For more ambiguous labeling tasks, you can use EffortLevel.MEDIUM or EffortLevel.HIGH to get higher quality labels from smarter models using the web. The cost scales accordingly, but even at higher effort levels, LLM labeling remains cheaper and faster than human annotation.
Reproduce this experiment
The full pipeline is available as a companion notebook on Kaggle. The experiment uses the DBpedia-14 dataset, a 14-class text classification benchmark. See also the full blog post for additional discussion.
Related
- How to Classify DataFrame Rows with an LLM — label data at scale with
agent_map - How to Deduplicate Training Data in Python — clean ML datasets before training